
This post would briefly introduce the data lake and outline the best practices for building a data lake using AWS cloud services.
1.1 What is Data Lake?
A data lake is a centralized data platform that provides infrastructure and services to store, process, and analyze huge volumes of data from various sources. Data lake architecture allows us to store the data in raw and original format (as is) without any change and allows engineers to access it for further analysis and processing. The storage infrastructure of the data lake is designed to scale to support the rapid growth of data volume, and also support a variety of formats and use cases that are unforeseen. This allows engineers to process the data quickly and make them available in a quick turnaround. The source data can be relational, structured, semi-structured, or unstructured. Interactive query services and data catalogs allow engineers and users to access the data using simple queries without worrying about the format of the source data.
It might sound like data lake is bringing us back to the traditional approach of file-based systems. However, a data lake in reality brings the capability of storing structured and unstructured data as-is with ease and analyzing data using readily available interactive query and analytics tools. Data lake also extends a variety of modern world use-cases on data science and analytics. The need for rapid processing and immediate availability of data has become crucial for business users to make decisions and support customers in getting deeper insights. Users can’t wait for a longer development cycle to get the required insights from raw data to arrive at decisions or arrive at answers to business problems.
1.2 Data Lake vs Data Warehouse
| Data Warehouse | Data Lake |
| Schema on Write – A careful design and cautious effort are needed before integrating data. | Schema on reading – Data can be stored as-is and has zero wait time for bringing in raw data to the data lake. |
| Data is processed and transformed – Data quality is assured. | Raw data – quality of data is not guaranteed. |
| Created for solving a set of known problems and use cases. | Not purpose-built but provides quick access to data for any use cases. |
| Highly expensive storage and computing resources are required. Scalability is challenging or questionable in accessing data beyond the petabyte scale. | Provides low-cost storage and compute resources. Easily scalable and can be extended for multiple and unknown use cases. |
Note: For modern and cloud data warehouses most of the differences are the same as above except for the scalability. Cloud data warehouses are addressing most of the limitations of traditional warehouses. However, there is always a need for a data lake to better manage raw data at a lower cost with a quick turnaround.
1.3 Data Lake Architecture – AWS
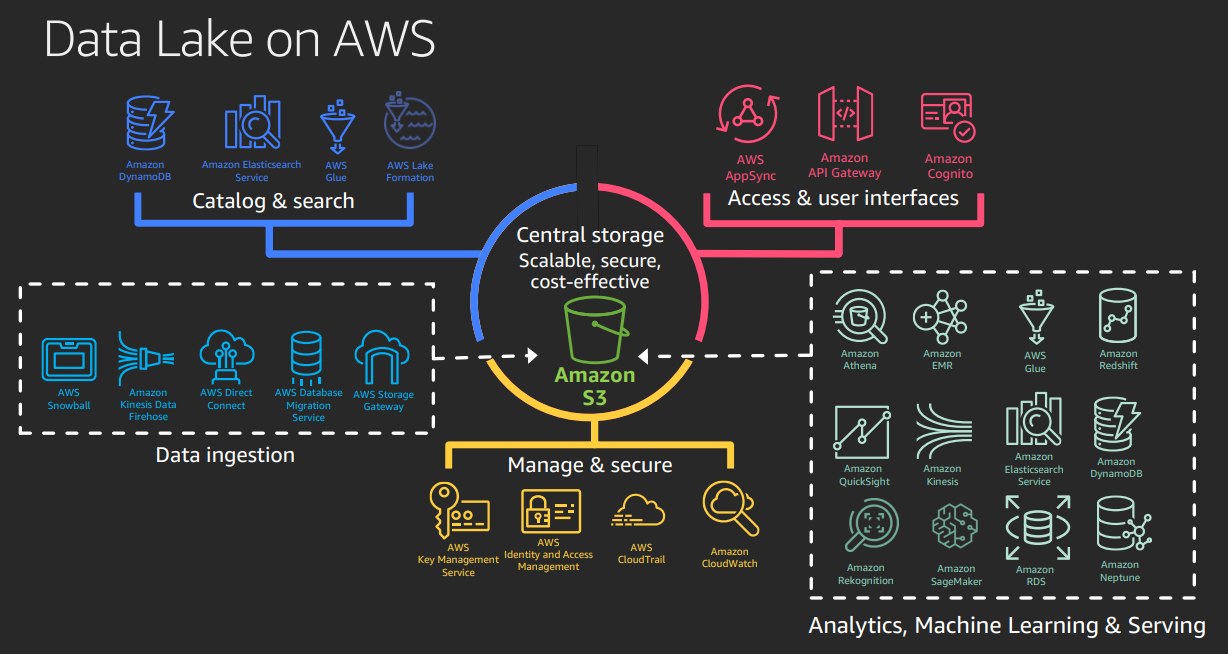
Central Storage: Provides scalable, secure, and low-cost infrastructure. S3 is the recommended storage. There are other choices – EMR and custom clusters.
Catalog and Search: The glue catalog can be used as a data catalog. However, for detailed catalog and searching, we can use dynamodb or AWS open search.
Access and User Interface: Services and interfaces for accessing and managing data platform APIs.
Data Ingestion and processing: Services for ingesting & processing data in the data lake (AWS Glue, Kinesis, EMR, Snow family, DMS, and storage gateway)
Manage and Secure: Services for Access Management, Encryption, logging, and monitoring – IAM, KMS, Cloud Trail, and Cloud Watch.
Analytics, ML, and Serving: Services for interactive queries, machine learning, visualization, analytics, data warehouse, and storage solutions (SageMaker, QuickSight, EMR, Kinesis, Athena, Redshift, RDS, Neptune, Dynamo DB)
Best Practices for AWS-Based Data Lake
A successful data lake implementation requires solid monitoring and governance. Best practices and standards around various components and processes need to be defined and enforced. To ensure the quality and usability of the data, it is crucial for an organization to define and enforce standards and best practices. AWS and other cloud services provide limitless options to process and use data effectively to extract the maximum business value. Though this gives huge benefits and reveals hidden opportunities, it is highly important to ensure security and governance for securing the positive outcome from the data platforms.
Storage best practices
- Prefer S3 as it is the most recommended storage from a cost and performance perspective by AWS.
- Define and enforce standards (naming and permissions) for bucket level and prefixes.
- Always use a raw or landing zone for storing and archiving source files. This would help in re-processing files quickly without hindering the source system. Often the users and down streams would require new attributes, business rules, and standardization.
- Maintain a separate layer for standardized and cleansed data – Standardization or curated layer.
- Define life cycle policies – older and less frequently accessed data can be moved to AWS S3 Glacier and cheaper storage classes.
- Always prefer columnar storage with compression except for raw or landing zones.
- Maintain separate storage for logging for ETL and data processing. Athena or any other query tool should have a separate bucket.
- Athena and other ad hoc query logs and output need to be purged on a regular basis. An automated process is preferred for this cleanup.
Data Processing
- Use streaming and messaging only for real-time use cases.
- Event-driven architecture patterns using serverless solutions like Glue, Lambda, and Step functions are highly recommended.
- EMR can be preferred if there are more use cases around huge volumes that are memory intensive and often cause issues with spark.
- Always have a landing zone with protected access at an object (folder prefix) per source system.
- FTP is preferred for third-party and other sensitive data. Consider using Direct Connect or other options before adding intermediate layers in case of on-premise data source integration.
- Use lambda and glue python shell for processing of lower volumes of data.
- Use spark and EMR for processing huge volumes of data.
Security
- Access should be denied by default. Always give access only to intended users, roles, and processes via policies at IAM roles. Avoid overriding policies manually at the role level or user level. Policy changes should go through a development life cycle and automation process.
- Always enable “Block Public Access” for S3 buckets at the organization level.
- Enable MFA to authenticate and use MFA for deletes
- Enable versioning and audit logging for better tracking and recovery in case of accidental issues that cause data loss or corruption.
- Encrypt data by default and enforce data encryption strictly.
- Use KMS with customer-managed keys and define a process for key rotation at defined intervals.
Performance and Scalability
- Do not use lambda for long-running processes
- For processing lower volume and long-running processes, use python shell.
- Define Retry logic for all the processes with a minimum. In a system with a huge number of jobs running at more frequent intervals, it is possible that jobs might fail with timeout and other resource contention issues. A retry mechanism and careful selection of scheduled frequencies could help reduce the maintenance overhead during such issues.
- Optimize a maximum number of rows per file – use group size parameter or coalesce function to reduce partition size.
- With AWS Glue, Avoid using gzip as it would not support automatic file splitting and reduces performance.
- Enable and Use Spark Web UI for analyzing and troubleshooting performance issues as it would give clear visualization of the execution plan.
- With Glue Jobs, Parameterize group size, DPU capacity, Worker Type, and the number of workers. For Python Shell Jobs, use DPU capacity.
DevOps
- Use Infrastructure as code with automation to handle lower-level component changes.
- Any changes in the data lake changes and configurations should go over DevOps (infrastructure changes/additions, code, policy changes, role changes and additions, km changes)
- Code branching strategy to cover all the environment changes including DEV, QA, TEST, UAT, and Production environments. Merging code from feature level to environment level branches should go through a PR and approval process.
- A clear rollback strategy is to be defined for each deployment.
Governance
- Define the purpose and use cases of the system.
- Building a data operations team should own the monitoring and support of data lake and data engineering processes.
- An architecture and SME team are responsible for reviewing and auditing the changes across the data lake. The selection and use of services need to be carefully reviewed and approved.
- Data stewards or Data Analysts along with business users own the data quality and business metadata of the data platform.
- New sources, systems, and processes should be reviewed and approved by the architecture and governance team.
- Strictly prevent the data lake storage is not used for logging or any other purposes other than the meaningful and accepted sources.
- Access and configurations need to be monitored and a clear process should be defined for changes in accesses and configurations.
- Enable audit and automated alerts or key metrics including cost, data processing (deletes, renaming), etc
- Renaming or removal of buckets or jobs or any other layers needs to go over a review and approval process as it could affect logging, monitoring, and other automated processes.
Catalog and Search
- For maintaining detailed business metadata, DynamoDB or Open Search can be used. A regular and periodic update of metadata changes can be automated as part of the deployment and release process.
- With Athena, create databases, tables, and columns with comments at all levels wherever possible. This could help the users to understand the purpose of data and use it effectively.
- Maintain separate databases for different layers and sources which helps in controlling access and organizing data.
Conclusion
The cloud is a great resource for data warehousing and business intelligence solutions. Data warehouses are essential for organizations that need to store large amounts of data for long periods of time. The cloud has been a great option for businesses that want to scale their data warehouses quickly and easily. AWS has gotten many businesses started with data warehousing solutions with their data lake best practices.








